
Network Resiliency in Private Cloud: (part 1 – the why)
Network Failures are Inevitable. This post will help you plan for them and make them non-existent to your customers.
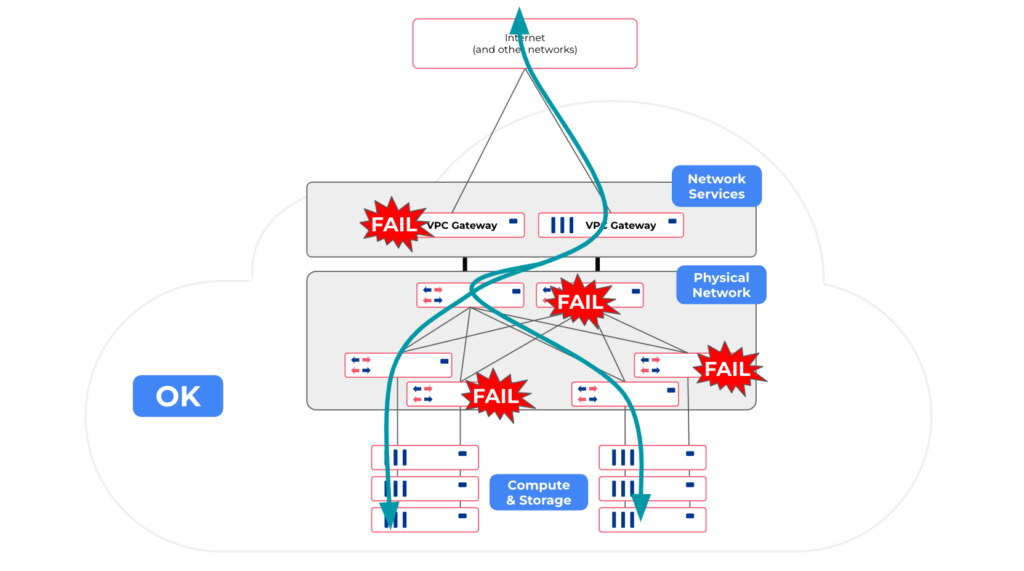
Why ?
In a public cloud, you take resiliency for granted (outside of full zone or regional outages). You don’t think about the redundancy of an elastic load balancer, your default gateway, your network firewall, your DHCP, or routing, or anything like that. Network services are highly available by default across availability zones within any region. That’s because users only deal with high-level abstractions, and the network automation algorithm running under the hood takes care of everything by automatically implementing control plane configurations in a resilient way.
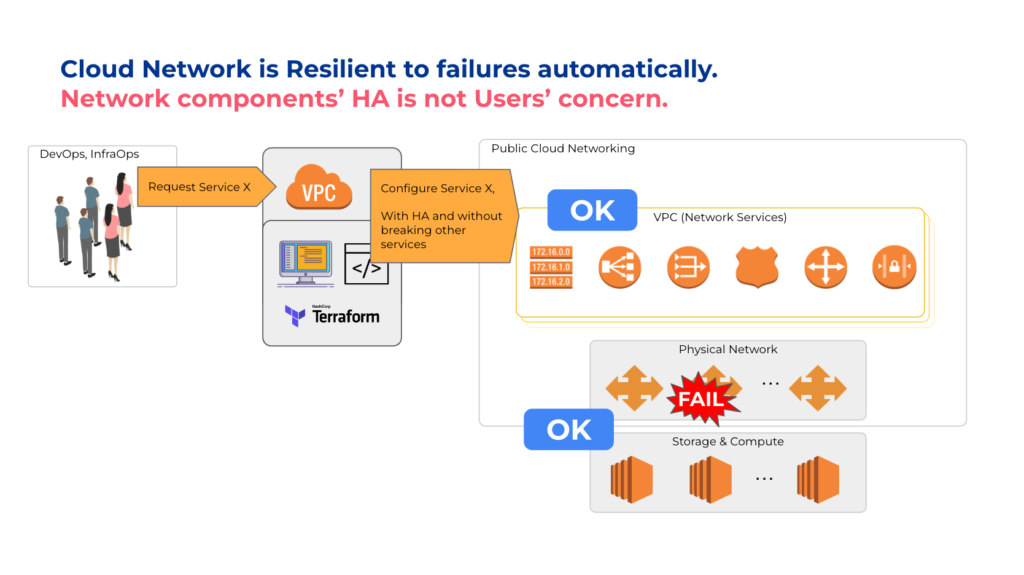
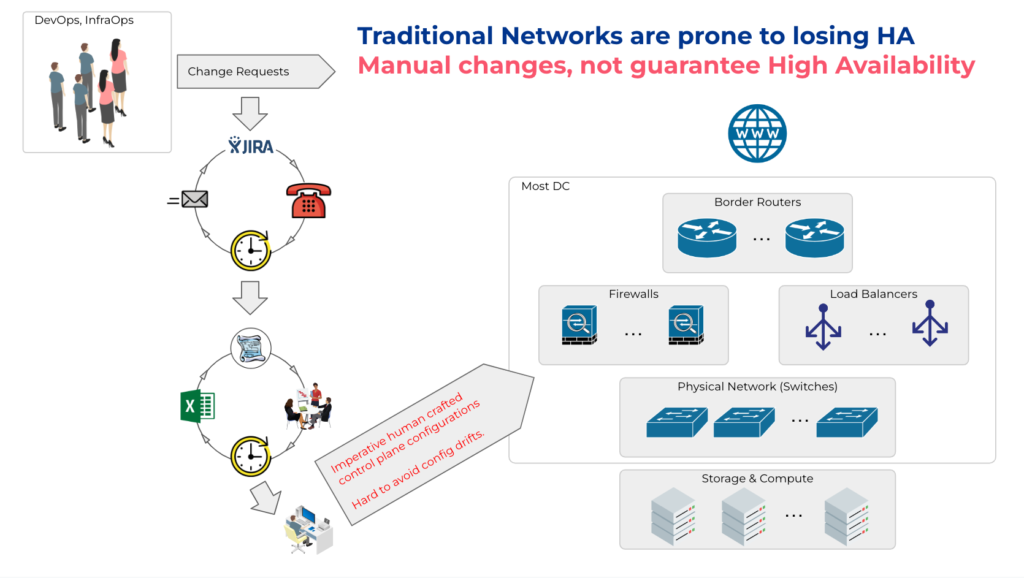
What if you are designing a private cloud on-prem in a colocation facility, on bare metal, or somewhere at the edge? Most people doing this use traditional networking technologies such as Cisco, Juniper, F5, etc., some load balancers, some firewalls, DNS servers, DHCP servers, some switches, and maybe even spreadsheets for IP address management.
Most automation tools for on-prem are strictly imperative. They distribute and apply configurations, but they don’t manage the entire lifecycle of the target system. Homegrown automation systems based on Ansible, Puppet, Chef, etc, are fire-and-forget. If someone makes a change out of the band, it will go unnoticed until the next configuration push, overwriting the production configuration in the process. Imperative tools rely solely on just-in-time automation and often expose low-level details instead of abstracting them away, so network engineers handcraft configuration changes. Such manual changes to production networks require planning and patience for every change. Even for the most experienced engineers, this introduces room for human error and buries the whole self-serviceability concept.
Two things make network services resilient in the public cloud:
- VPC networking abstraction
- Built-in network automation
These two advances allow cloud providers to leverage commodity hardware and focus on redundancy at the hardware level and reliability using the software. Linux has become the default network operating system and has evolved to take advantage of network-optimized hardware and regular servers with SmartNIC, which can forward enough network traffic to effectively replace specialized network hardware. In addition to Linux, the open-source community has produced industry standards around networking protocols, service proxies, and automation tools that have democratized large-scale networking. We work closely with organizations of various sizes who also took advantage of these advancements and are leveraging XDP, eBPF, DPDK, FRR, Wireguard, ISC Kea, Envoy, and other open-source technologies for their mission-critical networks. The key is to program these tools automatically to work together in concert and expose a cloud-like VPC abstraction to the users. When users manage the system declaratively through the abstraction layer (VPC) and rigorously tested algorithms handle all imperative work, there’s no risk of configuration drifts and other human errors. The same concept of exposing a declarative abstraction to the user and letting the control plane self-configure automatically is core to Kubernetes.
There are various ways to organize the resiliency of network services. In this article, we describe how we designed high availability under the hood of Netris based on learnings from a multitude of customers who are using Netris for running private cloud deployments of 10 to 10,000 servers.
A quick throwback to network high availability history
Before founding Netris, I had many network engineering jobs where I dealt with failover mechanisms for switches, firewalls, load balancers, and routers made by Cisco, Juniper, F5, Dell, Ericsson, and a few others. Each vendor has its differences, and there are many standard and proprietary techniques for high availability. I like to categorize those failover mechanisms into two simple groups.
- Single virtual cluster – stacking, clustering, virtual chassis, HA cluster, and other terms are used by vendors to describe various technologies. In essence, these are all techniques for logically combining multiple devices into a single virtual entity so engineers manage one thing instead of many things. I have investigated a multitude of disastrous cases where this approach failed production. The main downside to this virtual cluster approach is that although you have multiple devices, all devices share common control plane components, creating a potential for a single point of failure. So, for example, failure of the dynamic routing protocol will affect all nodes, not just one. Or failure of some process that is monitoring the liveness of some service will affect all nodes. The same applies to human-made configurations. Changes apply globally, and one error immediately amplifies across all nodes in the cluster.
- Redundant nodes – Two or more nodes (routers, firewalls, gateways) are constantly ready to forward traffic and use routing techniques to signal neighboring hosts or nodes that they are clear to serve their traffic. Assuming you correctly configure every node every time you make changes, you have better availability. There’s no common control plane, so there is no single point of failure. But the problem here is that configuration-wise, you are dealing not with one virtual node but you are dealing with a multitude of nodes. (2x routers, 2x firewalls, 2x load balancers, NNx switches, etc…) Sometimes network engineers make a change in config to implement a request, and they are not 100% sure if the failover mechanism is still ok or not after the change. You cannot perform failover tests after every change – because it’s a mission-critical production. So you hope it’s ok – but no one knows.
These techniques were ok for the time they were designed. Today, neither of these legacy approaches is suitable for highly dynamic private cloud environments.
Netris approach:
- Every node is always ready to forward traffic independently.
- There is no memory or state replication, so a failure of one node can not affect others.
- Imperative configurations of network nodes happen automatically by Netris algorithms – not directly by humans. No room for misconfiguration, config drifts, or human errors.
- Failover mechanisms enable automatically – It’s not an engineer’s concern. Engineers only need to provide the required number of hardware – and the Netris software running on it will automatically program the control plane of each device for resiliency.
Because all network configs are generated by the software automatically, and our users don’t make any imperative configurations, there is no room for failover degradation caused by human misconfiguration.
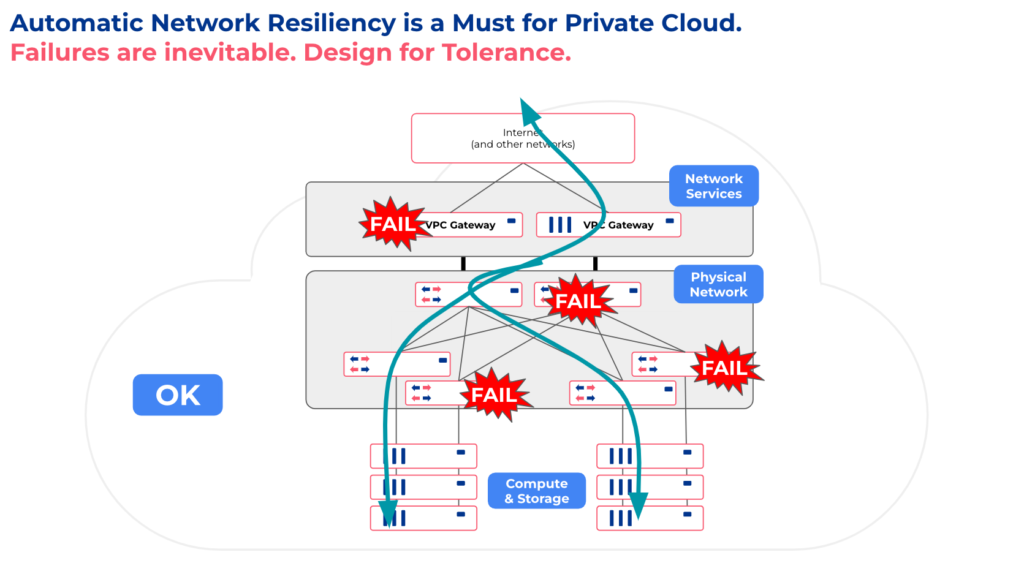
Conclusion
In the next blog, I’ll go into the details of how we accomplish this. Check out the part 2 here.

Author: Alex Saroyan
CEO/co-founder at Netris


